

VGG网络 学习笔记
论文信息
论文链接:Very Deep Convolutional Networks for Large-Scale Image Recognition
论文作者:Karen Simonyan、Andrew Zisserman
摘要:
本研究探究了卷积神经网络深度对大规模图像识别准确率的影响,证实增加网络深度至 16–19 个权重层并采用 3×3 卷积核可显著提升性能,相关模型在 2014 年 ImageNet 挑战赛中斩获佳绩且已开源,其特征表示在其他数据集上也表现优异。
论文拆解
1. Introduction
没啥内容。我用自己的话概括了一下:
卷积神经网络近年来在大规模图像和视频识别方面取得很大成功。很多人在研究如何提升其性能和准确率。我们研究发现,增加网络深度(通过将卷积核减小为 3x3 以实现)可以提升模型表现,该模型在 ImageNet 分类与定位任务中表现顶尖。
2. ConvNet Configurations
本节介绍了 VGG 的网络架构。
- 输入:
RGB 图像; - 训练预处理:去均值;
- 卷积核:堆叠好多层,大小
,步幅 ,填充 (有 个模型用了 卷积); - 所有隐藏层使用
ReLU激活函数; - 池化层:共
个最大池化层,大小 ,步幅 ; - 全连接层:共
层,通道数为 ,最后一层 是因为分类数为 ; - 最后用
soft-max层作为输出层; - 基本不使用
LRN归一化(因为没效果,还浪费内存和计算资源)。
具体结构见下表(图片来自论文):
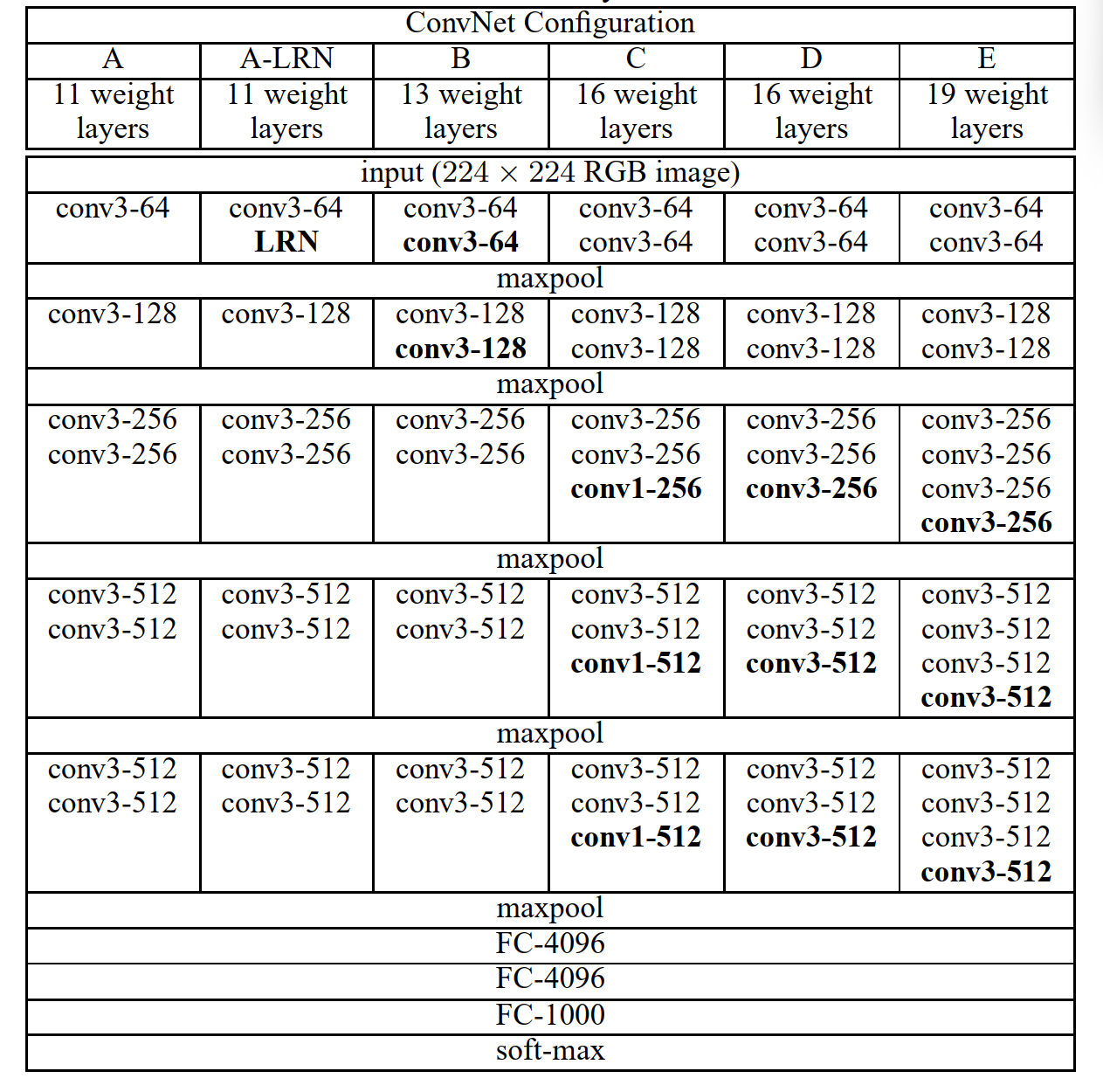
上图中,池化层都不算入层数中。表格中的卷积层参数表示为 conv⟨感受野大小-通道数⟩。为了简洁起见,在表格中不显示 ReLU 激活函数。在这篇论文中分别使用了 A、A-LRN、B、C、D、E 这
其中,网络结构 D 就是著名的 VGG 16,网络结构 E 就是著名的 VGG 19。
论文接下来指出,VGG 架构和此前 ILSVRC 赛事的优秀模型存在显著差异:VGG 全程使用
堆叠
- 引入更多非线性整流层,让模型的决策函数更具判别性。
- 大幅减少了参数数量。以输入输出均为
通道为例, 层 卷积的参数总量为 ,远低于 层 卷积的 。
此外,该架构还融入
对比同类工作,此前使用小卷积核的模型网络深度远不及该研究,且未在大规模 ILSVRC 数据集上验证;而同期 ILSVRC-2014 的优秀模型 GoogLeNet 虽同样采用小卷积核与深层结构,但拓扑更复杂,且早期层对特征图分辨率压缩更激进,该研究提出的模型在单网络分类精度上优于 GoogLeNet。
3. Classification Framework
本节描述了 VGG 网络在分类任务中训练和评估过程的细节。
训练
基本范式
- 采用 mini-batch SGD(batch size =
)+ momentum( ),目标函数为多分类 softmax。 - L2 权重衰减:
。 - Dropout:仅用于前两个全连接层,比例
。 - learning rate 初始为
,验证集精度不再提升时就乘以 ,共下降 次。 - 总训练
iterations(74 epochs)。深层网络能更快收敛,作者认为有这两个原因:(a)深度 + 小卷积核 -> 隐式正则化;(b)部分层的预初始化。
权重初始化
- 先训练较浅的配置 A(可随机初始化)。
- 训练更深网络时:
- 继承 A 的前
个卷积层 + 后 个全连接层; - 中间层随机初始化;
- 不降低预处理层的学习率,允许其继续更新。
- 继承 A 的前
- 随机初始化:
- 权重 ~
,bias 为 。
- 权重 ~
- 备注:后续发现 Glorot 初始化可避免预训练。
数据
数据增强
- 输入大小固定为
; - 每次 SGD,从缩放后的图像中随机裁剪,随机水平翻转,随机 RGB 颜色抖动;
训练尺度
- Let
:= 缩放后图像的最短边。 - 若
,代表整图;若 ,代表小目标。
采用以下两种方法设置训练尺度:
- 单尺度训练(single-scale):
- 固定
。 - 实验时,使用了
和 。 - 先训练
模型,再用它初始化 模型的权重,后者用更小的初始学习率( )。
- 固定
- 多尺度训练(multi-scale):
- 每张训练图像随机采样,
。 - 作者认为其本质是尺度抖动(scale jittering)的数据增强 + 用一个模型适配多尺度目标。
- 实现方式:在
单尺度模型上 fine-tune。
- 每张训练图像随机采样,
测试
- 测试图像缩放到最短边
。( 可以不等于 )。 - 将全连接层转为卷积层:
- FC1
conv; - FC2 & FC3
conv。
- FC1
- 对整张图像密集卷积。
- 输出 class score map:
The result is a class score map with the number of channels equal to the number of classes, and a variable spatial resolution, dependent on the input image size.
- 最终预测:对 score map 做空间平均池化(sum-pooled)。
- 测试时增强:
- 水平翻转;
- 原图和翻转图的 softmax 结果取平均。
- 作者用一大段论述了为何不做多裁剪(multi-crop)。
Implementation Details
没啥好讲的,直接摘论文了:
Our implementation is derived from the publicly available C++ Caffe toolbox (Jia, 2013) (branched out in December 2013), but contains a number of significant modifications, allowing us to perform training and evaluation on multiple GPUs installed in a single system, as well as train and evaluate on full-size (uncropped) images at multiple scales (as described above). Multi-GPU training exploits data parallelism, and is carried out by splitting each batch of training images into several GPU batches, processed in parallel on each GPU. After the GPU batch gradients are computed, they are averaged to obtain the gradient of the full batch. Gradient computation is synchronous across the GPUs, so the result is exactly the same as when training on a single GPU.
性能效果:
4. Classification Experiments
本节展示了 VGG 网络在 ILSVRC-2012 dataset 上的图像分类表现结果,及一些有意义的发现。
数据集与评测标准
- 数据集:ILSVRC-2012
- 类别数:
- 训练集:
- 验证集:
- 测试集:
(无标签)
- 类别数:
- 评测指标:
- Top-1 error:预测
实际 - Top-5 error:真实标签不在预测前
- Top-1 error:预测
多数实验在 validation set 上完成,部分结果提交至 ILSVRC-2014 官方测试集。
单尺度评测(Single Scale Evaluation)
First, we note that using local response normalisation (A-LRN network) does not improve on the model A without any normalisation layers. We thus do not employ normalisation in the deeper architectures (B–E).
发现 LRN 没用,于是后续 B-E 都不做归一化。
Second, we observe that the classification error decreases with the increased ConvNet depth: …
分类误差随网络深度(从 A 的
根据实验结果(比较不同模型表现),有以下重要结论:
- 仅增加非线性不够,必须扩大有效感受野;
- 多层小卷积核
少层大卷积核
Finally, scale jittering at training time leads to significantly better results than training on images with fixed smallest side, even though a single scale is used at test time. This confirms that training set augmentation by scale jittering is indeed helpful for capturing multi-scale image statistics.
尺度抖动是一种极其有效的数据增强方式。
多尺度评测(Multi-Scale Evaluation)
对测试方法不太感兴趣,所以在此不表。
As can be seen, using multiple crops performs slightly better than dense evaluation, and the two approaches are indeed complementary, as their combination outperforms each of them. As noted above, we hypothesize that this is due to a different treatment of convolution boundary conditions.
直接说结论吧,多尺度训练 + 多尺度测试效果最好。
模型融合(ConvNet Fusion)
Up until now, we evaluated the performance of individual ConvNet models. In this part of the experiments, we combine the outputs of several models by averaging their soft-max class posteriors. This improves the performance due to complementarity of the models, and was used in the top ILSVRC submissions in 2012 (Krizhevsky et al., 2012) and 2013 (Zeiler & Fergus, 2013; Sermanet et al., 2014).
结论:少量强模型 > 大量一般模型
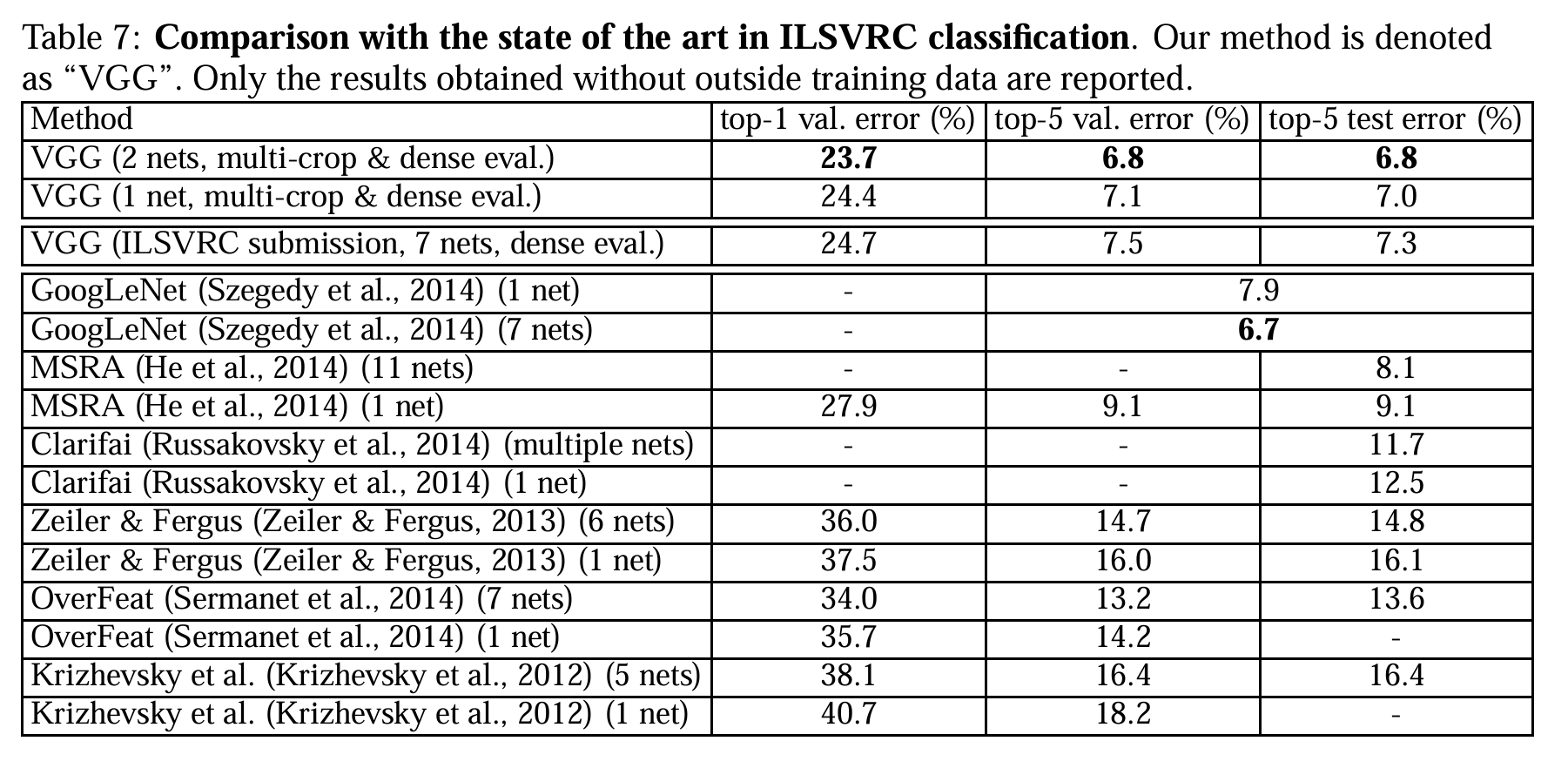
对比 SOTA
ILSVRC-2014 第二名,top-5 test error
5. Conclusion
It was demonstrated that the representation depth is beneficial for the classification accuracy, and that state-of-the-art performance on the ImageNet challenge dataset can be achieved using a conventional ConvNet architecture (LeCun et al., 1989; Krizhevsky et al., 2012) with substantially increased depth.
不靠复杂的网络结构,仅仅靠增加深度,就能够提升视觉识别性能。
论文复现
PyTorch 实现 VGG 模型
很简单,对着论文里的架构搓就行了,写法借鉴了一些网上的实现。
import torch |
训练 & 评估
跑 ILSVRC-2012 肯定不可能,跑 CIFAR-10 这种小数据集也有大炮打蚊子之嫌,决定等找到合适的数据集后再补。
- 标题: VGG网络 学习笔记
- 作者: Coast23
- 创建于 : 2025-12-14 13:25:43
- 更新于 : 2026-01-30 15:36:06
- 链接: https://coast23.github.io/2025/12/14/VGG网络-学习笔记/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。